2080 Ti Erscheinungsdatum
Der größere Aspekt dieser Nachricht ist jedoch, dass die proprietäre GPU -Interconnect von NVIDIA, Cache Cohärent, zu Konsumkarten kommen wird. Die GeForce GTX -Karten implementieren SLI über NVLink, wobei 2 NVLink -Kanäle zwischen jeder Karte ausgeführt werden. Bei einer kombinierten 50 GB/Sek. Full-Duplex-Bandbreite-was bedeutet. Dies ist über den anderen NVLINK -Feature -Vorteilen, insbesondere die Cache -Kohärenz. Und all dies kommt zu einem wichtigen Zeitpunkt, da die Bandbreitenanforderungen zwischen-GPU mit jeder Generation weiter steigen.
Nvidia Geforce RTX 2080 Ti Graphics Card
Modded Geforce RTX 2080 TI unterstützt 22 GB GDDR6 -Speicher
Teclab Breaks 3GHz GPU -Uhr Barriere mit GeForce RTX 2080 Ti
Nvidia wurde gemunkelt, Geforce RTX 2080 (TI/Super) und Geforce RTX 2070 (Super) Grafikkarten in den Ruhestand zu nehmen
MSI Outs Geforce RTX 2080 Ti Gaming Z mit 16 Gbit / s GDDR6 -Speicher
Nvidia kündigt Geforce RTX 2080 Ti ‘Cyberpunk 2077 Edition an
Asus zeigt Geforce RTX 2080 Ti ROG Strix White Edition
Gigabyte startet Aorus Gaming Box mit RTX 2080 Ti
Galax Geforce RTX 2080 Ti Hof 10 -jährige Jubiläumsausgabe gepackt
MSI RTX 2080 Ti Lightning 10 -jährige Jubiläumsausgabe Bild
MSI neckt Geforce RTX 2080 Ti Lightning 10 -jährige Jubiläumsausgabe
(PR) MSI kündigt Geforce RTX 2080 Ti Lightning Z an
Evga Geforce RTX 2080 Ti Kingpin Edition ist ein Hybrid
MSI Geforce RTX 2080 Ti Lightning abgebildet
ASUS präsentiert ROG Geforce RTX 2080 Ti Matrix
Buntes Geforce RTX 2080 Ti Igame Kudan lächelt für die Kamera
MSI neckt Kohlenstofffaser Geforce RTX 2080 Ti Lightning Z
Zotac Geforce RTX 2080 Ti Arcticstorm zum Debüt bei CES 2019
MSI Geforce RTX 2080 Ti Lightning Z PCB Abgebildet
Farbenfrohe Starts Geforce RTX 2080 (TI) RNG Edition mit Full Color LCD
(PR) Inno3d kündigt Geforce RTX Ichill Frostbite -Serie an
Evga neckt Geforce RTX 2080 Ti Kingpin
Gigabyte Vorbereitung von Geforce RTX 2080 Ti aorus Turbo
Nvidia bündelt Battlefield V mit Geforce RTX kostenlos
(PR) Manli kündigt Geforce RTX 2080 TI & 2070 mit Blower -Lüfter an
Neuer Kartenbericht Nr. 21: Die RTX RGB Edition
Inno3d verwandelt Geforce RTX -Karte in einen riesigen RGB -Weihnachtsbaum
MSI kündigt Geforce RTX 2080 (TI) Sea Hawk (EK) X -Serie an
Gigabyte neckt Geforce RTX 2080 (TI) AORUS Graphics Card
NVIDIA GEFORCE RTX 2080 TI & RTX 2080 Überprüfungs Roundup
TechPowerup erklärt den Unterschied zwischen Turing A und Nicht-A-GPU-Varianten
Nvidia Geforce RTX 2080 TI und RTX 2080 „Offizielle“ Leistung enthüllt
Die neuen Merkmale der Nvidia Turing Architecture
Nvidia Änderungen Geforce RTX 2080 Bewertungen Datum bis 19. September
Nvidia Geforce RTX 2080 Bewertungen gehen am 17. September live
EVGA enthüllt Hydro -Kupfer- und Hybrid -Geforce -RTX -Modelle
- 2025 GeForce 50 TBA
- 2023 Geforce 40 Mobile
- 2022 Geforce 40
- 2021 GeForce 30 Mobile
- 2020 Geforce 30
- 2019 Geforce 16
- 2019 Geforce 16 Mobile
- 2018 Geforce 20
- 2018 GeForce 20 Mobile
- 2016 Geforce 10
- 2016 Geforce 10 Mobile
- 2014 Geforce 800 Mobile
- 2014 Geforce 900
- 2014 Geforce 900 Mobile
- 2013 Geforce 700
- 2013 Geforce 700 Mobile
- 2012 Geforce 600
- Rechenzentrum / Tesla
- Tegra
- Workstation / Quadro
- Geforce MX
- Titan RTX
- GeForce RTX 2080 Ti
- Geforce RTX 2080 Super
- GeForce RTX 2080
- Geforce RTX 2070 Super
- GeForce RTX 2070
- Geforce RTX 2060 Super
- GeForce RTX 2060 12 GB
- GeForce RTX 2060
- GeForce MX250
- 3D -Stapel
- Zubehör
- Ankündigungen
- Apfel
- ARM
- Künstliche Intelligenz
- Automobilindustrie
- Benchmarks
- Business & Markets
- Chinesische Grafiken
- Konzepte
- Konnektivität
- Inhaltserstellung
- Kühltechnologie
- Kryptowährung
- Benutzerdefinierte Projekte
- Angebote
- Anzeigen und Monitore
- Veranstaltungen
- Externe GPUs und Gehege
- Externe Bewertungen
- Extremes Übertakten
- Finanzielle Ergebnisse
- Gießereien
- Spielbündel & Angebote
- Spielanforderungen
- Spielstreaming
- Spiele
- Spielkonsolen
- Gaming -Hardware
- Grafik
- Grafik -APIs
- Interviews
- Linux
- Speichertechnologie
- Mini/SFF/NUC -PCs
- Mobile Geräte
- Modding
- Motherboards
- Notizbücher
- Patente & Forschung
- PC -Fälle
- PCI Express
- Menschen
- Netzteile
- Vorgebaute Systeme
- RISC-V
- Sicherheit
- Software und Treiber
- Lagerung
- Superauflösung
- Supercomputing (HPC)
- Videocodierung
- Virale Geschichten
- Virtuelle Realität
- Wasserkühlen
- 2025 Radeon 8000 TBA
- 2023 Radeon 7000 Mobile
- 2022 Radeon 7000
- 2021 Radeon 6000 Mobile
- 2020 Radeon 6000
- 2019 Radeon 5000
- 2019 Radeon 5000 Mobile
- 2017 Radeon 500
- 2017 Radeon 500 Mobile
- 2016 Radeon 400
- 2016 Radeon 400 Mobile
- 2015 Radeon 300
- 2015 Radeon 300 Mobile
- 2014 Radeon 200 Mobile
- 2013 Radeon 200
- Radeon Instinkt
- Radeon Pro
- Blockchain -Berechnung
- 2025 GeForce 50 TBA
- 2023 Geforce 40 Mobile
- 2022 Geforce 40
- 2021 GeForce 30 Mobile
- 2020 Geforce 30
- 2019 Geforce 16
- 2019 Geforce 16 Mobile
- 2018 Geforce 20
- 2018 GeForce 20 Mobile
- 2016 Geforce 10
- 2016 Geforce 10 Mobile
- 2014 Geforce 800 Mobile
- 2014 Geforce 900
- 2014 Geforce 900 Mobile
- 2013 Geforce 700
- 2013 Geforce 700 Mobile
- 2012 Geforce 600
- Rechenzentrum / Tesla
- Tegra
- Workstation / Quadro
- Geforce MX
- 2025 Arc Druid TBA
- 2024 Arc Celestial TBA
- 2023 ARC Battlemage TBA
- 2022 Arc Alchemist
- 2022 Intel Data Center HPC TBA
- 2021 Intel Data Center HP TBA
- 2020 Intel XE-LP
- ARC Pro
2080 Ti Erscheinungsdatum
Offizielle NVIDIA RTX 2080 TI, 2080 und 2070 Spezifikationen, Preis, Erscheinungsdatum
Von Steve Burke veröffentlicht am 20. August 2018 um 15:00 Uhr

Aktualisieren: Eine Korrektur für SM / CUDA -Kernzahlen hinzugefügt, da die vollständigen Details durchgesickert sind.
NVIDIA kündigte heute seine neuen Turing -Grafikkarten für Gaming an, einschließlich der RTX 2080 TI, RTX 2080 und RTX 2070. Die Karten treten mit einer verbesserten, aber vertrauten Volta-Architektur mit einigen Änderungen an SMS und Speicher voran. Das neue RTX 2080 und 2080 Ti -Schiff zuerst mit Referenzkarten und Partnerkarten weitgehend gleichzeitig (mit einigen fortgeschritteneren Modellen, die 1+ Monat später kommen), Abhängig davon, welcher Partner ist. Die Board -Partner erhielten bis ungefähr zur gleichen Zeit wie die Medien keine Preisgestaltung oder gar Kartennamen. Erwarten Sie daher Verzögerungen in benutzerdefinierten Lösungen. Beachten Sie, dass wir ursprünglich eine 1-3-monatige Latenz auf Partnerkarten gehört haben, aber das scheint nur für fortschrittliche Modelle zu sein, die gerade in die Produktion eintreten. Die meisten Tri-Fan-Modelle sollten am selben Datum verfügbar sein.
Ein weiterer wichtiger Betrachtungsgrund ist die Entscheidung von Nvidia, eine doppeltaxiale Referenzkarte zu verwenden, wodurch ein Großteil des Werts von Partnerkarten am Low-End-. Wenn Sie sich von den Referenzkarten von Gebläber und Dual-Fan-Karten entfernen, werden die Partner des Verwaltungsrats am unmittelbar beeinflusst, was dazu führen könnte. Der RTX 2080 TI kostet 1200 US -Dollar und wird am 20. September mit dem 2080 für 800 US -Dollar (und 20. September) und dem 2070 für 600 US -Dollar (TBD -Veröffentlichungsdatum) gestartet.
Nvidia RTX 2080 TI & 2080 Spezifikationen
Einer der größten Fehler, den die Menschen beim Vergleich neuer GPUs machen, besteht darin, über „Kernzählung zu sprechen.„Dies ist aus wenigen Gründen falsch, von denen eine Kernleistung nicht identisch ist, die die Kreuzarchitektur. Von Kepler bis Pascal gab es für die Effizienz des Gesamtleistung von Per-Watt-Effizienz von über 30%, und nur einen linearen Vergleich zwischen den Kernzählungen enthält dies nicht. Auch Cuda -Kerne sind es nicht Wirklich Wie auch immer Kerne: Sie sind schwimmende Punkteinheiten. Ein SM wäre einem Kern nach Standarddefinitionen ähnlicher, die dazu führen, dass ein Kern in der Lage ist, Anweisungen abzurufen und zu entschlüsseln, diese auszuführen, Daten zu und von Registern und Cache zu lesen und Ergebnisse zu berechnen, und die Ergebnisse der Rechnung zu stellen. Nvidias schwimmende Punkteinheiten können Ergebnisse berechnen, können aber nicht viel von den anderen Zügen tun.
Der Punkt, all dies zu sagen, ist, dass ein strenger Pascal vs. Turing Core -Vergleich muss architektonische Unterschiede berücksichtigen, die sich ändern könnten, wie gut ein „Kern“ funktioniert. Die Leute fielen das letzte Mal in die gleiche Falle.
NVIDIA RTX 2080 TI, 2080 & 2070 Founders Edition Spezifikationen
NVIDIAs neue RTX 2080 TI-Hosts 4352-Gleitkomma-Einheiten, wobei die RTX 2080 Non-TI-Hosting 2944 FPUs veranstaltet. Nvidia hält sich an 64 FPUs pro Streaming -Multiprozessor, die den 2080 Ti mit 68 SMS mit dem 2080 bei 46 SMS belegten. Nvidia hat die SM -Architektur für diese GPU überarbeitet, daher sind wir noch nicht positiv auf alle feineren Details.
Der neue GPUs wechselt auch zu GDDR6, einer erwarteten Verschiebung. Derzeit läuft GDDR6 um ungefähr 20% höhere BOM -Kosten als GDDR5, aber diese Kosten werden im Laufe der Zeit sinken. GDDR6 ermöglicht minimal 14 Gbit / s pro Pin -Durchsatz für die RTX 2080 und 2080 TI, ein bemerkenswerter Schub über die 8 -Gbit / s- und 10 -Gbit / s -Durchsatz bei früheren Generationen. GDDR6 kann auch bis zu 16 Gbit / s pro Pin drücken, aber es gibt kein sofortiges Versprechen für den neuen GPUs. Wir sind uns noch nicht sicher, ob GDDR6 Auswirkungen des Speicherzeitpunkts betrifft. Der 2080 Ti wird 11 GB GDDR6 in einem 352-Bit-Speicherbus mit einer Speicherbandbreite in der Nachbarschaft von 620 GB/s veranstalten. Der RTX 2080 veranstaltet 8 GB GDDR6 an einer 256-Bit-Schnittstelle und ermöglicht daher 448 GB/s Speicherbandbreite.
| RTX 2080 Ti | RTX 2080 | RTX 2070 |
| FP32 FPUs (“Cuda Cores”) | 4352 | 2944 | 2304 |
| Streaming -Multiprozessoren | 68 | 46 | 36 |
| Kernuhr / Boost -Uhr | 1350/1545
Fe: 1635 MHz | 1515/1710
Fe: 1800 MHz | 1410/1620
Fe: 1710MHz |
| Speicherschnittstelle | 352-Bit | 256-Bit | 256-Bit |
| Speicherkapazität | 11 GB | 8 GB | 8 GB |
| GDDR6 -Geschwindigkeit | 14gbit / s | 14gbit / s | 14gbit / s |
| Speicherbandbreite | 616 GB/s | 448 GB/s | 448 GB/s |
| Sli | NvLink 2-Wege | NvLink 2-Wege | TBD |
| TDP | ~ 265 ~ 285W | ~ 250-260W | 175-185W |
| Preis | $ 1.200
Oder $ 1000* | 800 $
Oder $ 700* | $ 600
Oder $ 500* |
| Veröffentlichungsdatum | September. 20, 2018 | September. 20, 2018 | TBD |
*Quelle für Preise: NVIDIA -Website. NOTIZ: Wir haben auch gehört, dass die Preise (möglicherweise für Nicht-Fe-Karten? Oder gibt es nur eine Misskommunikation innerhalb von Nvidia?) könnte auch 500 US -Dollar für die 1070, 700 US -Dollar für die 2080 und 1000 US -Dollar für den 2080 Ti betragen. Wir glauben, dass dies Fe vs sein könnte. Referenz, aber es könnte auch von den Nvidia -Teams zu Missverständnissen sein. Im Moment nicht klar.
Nvidia kündigt die Geforce RTX 20 Serie an: RTX 2080 TI & 2080 am September. 20. RTX 2070 im Oktober

Die Keynote Gamescom 2018 von NVIDIA ist gerade abgeschlossen, und wie viele seit seiner Bekanntgabe im letzten Monat erwartet haben, bereitet sich NVIDIA bereit, ihre nächste Generation von Geforce -Hardware zu starten. Angekündigt auf der Veranstaltung und zum Verkauf ab dem 20. September ist die Geforce RTX 20-Serie von NVIDIA, die die derzeitige Pascal-betriebene Geforce GTX 10-Serie auftritt. Basierend auf der neuen Turing -GPU -Architektur von NVIDIA und basiert auf dem 12nm -FFN -Prozess von TSMC. Nvidia hat hohe Ziele. Sie möchten eine gesamte Paradigmenverschiebung bei der Rendite von Spielen und der Bewertung von PC. CEO Jensen Huang hat die wichtigste GPU -Architektur von Turing Nvidia seit 2006 Tesla GPU Architecture (G80 GPU) bezeichnet. Aus Merkmal.
Wie traditionell sind die ersten Karten aus dem Nvidia-Stall die High-End-Karten. In einer ziemlich beträchtlichen Pause aus der Tradition werden wir nicht nur die X80- und X70 -Karten zum Start erhalten, sondern auch die X80 Ti -Karte. Dies bedeutet. Der Produktstack von NVIDIA bleibt hier unverändert, daher bleibt RTX 2080 Ti ihre Flaggschiff-Karte, während RTX 2080 ihre High-End-Karte ist, und dann RTX 2070 die etwas billigere Karte, um Enthusiasten zu verleihen, ohne die Bank zu brechen.
Alle drei Karten werden in den nächsten zwei Monaten gestartet. Zunächst wird der RTX 2080 TI und RTX 2080 sein, der am 20. September starten wird . Der RTX 2080 TI startet bei 999 US -Dollar für Partnerkarten, während der RTX 2080 bei 699 US -Dollar beginnt. In der Zwischenzeit wird der RTX 2070 irgendwann im Oktober mit Partnerkarten ab 499 US -Dollar gestartet. Auf historischer Basis sind alle diese Preise höher als die letzte Generation zwischen 120 und 300 US -Dollar. In der Zwischenzeit sind Nvidia’s eigene Referenzqualitäts-Gründer-Edition-Karten wieder zurück, und diese werden eine Prämie von 100 bis 200 US-Dollar gegenüber den Basispreisen tragen.
Leider nimmt Nvidia hier bereits Vorbestellungen an, sodass die Verbraucher im Wesentlichen einen „Blind Buy“ machen müssen. Nvidia hat überraschend wenig Informationen über die Leistung angeboten, und wir empfehlen, auf vertrauenswürdige Bewertungen von Drittanbietern zu warten (i.e. US), aber ich muss zugeben, dass ich mir nicht vorstellen kann, dass es viel Aktien gibt, die die Bewertungen auf die Straße machen werden.
| Nvidia GeForce -Spezifikationsvergleich |
| RTX 2080 Ti | RTX 2080 | RTX 2070 | GTX 1080 |
| Cuda -Kerne | 4352 | 2944 | 2304 | 2560 |
| Kerntakt | 1350 MHz | 1515 MHz | 1410 MHz | 1607 MHz |
| Schub Uhr | 1545 MHz | 1710 MHz | 1620 MHz | 1733 MHz |
| Speicheruhr | 14gbit / s GDDR6 | 14gbit / s GDDR6 | 14gbit / s GDDR6 | 10gbit / s GDDR5X |
| Speicherbusbreite | 352-Bit | 256-Bit | 256-Bit | 256-Bit |
| Vram | 11 GB | 8 GB | 8 GB | 8 GB |
| Einzelne Präzision perf. | 13.4 tflops | 10.1 tflops | 7.5 tflops | 8.9 tflops |
| Tensor Perf. | 440t Ops
(Int4) | ? | ? | N / A |
| Ray Perf. | 10 Grautöne/s | 8 Grautöne/s | 6 Grautöne/s | N / A |
| “RTX-Ops” | 78T | 60t | 45T | N / A |
| TDP | 250W | 215W | 175W | 180W |
| GPU | Big Turing | Unbenannt Turing | Unbenannt Turing | GP104 |
| Transistorzahl | 18.6b | ? | ? | 7.2B |
| Die Architektur | Turing | Turing | Turing | Pascal |
| Herstellungsprozess | TSMC 12nm “ffn” | TSMC 12nm “ffn” | TSMC 12nm “ffn” | TSMC 16nm |
| Erscheinungsdatum | 20.09.2018 | 20.09.2018 | 10/2018 | 27.05.2016 |
| Startpreis | UVP: $ 999
Gründer $ 1199 | UVP: $ 699
Gründer $ 799 | UVP: $ 499
Gründer $ 599 | UVP: $ 599
Gründer $ 699 |
Turing Architecture von Nvidia: RT & Tensor Cores
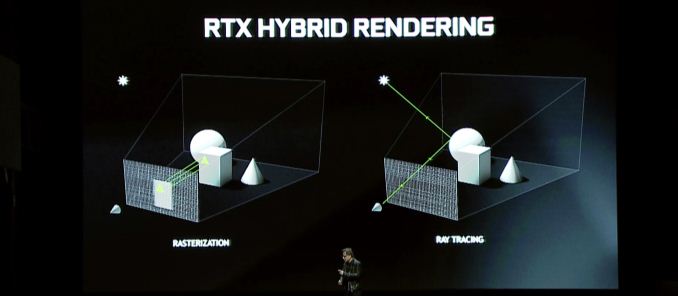
Was bringt Turing also auf den Tisch?? Das Festzelt -Feature auf ganzer Linie ist das Hybrid -Rendering, das die Strahlenverfolgung mit der traditionellen Rasterisierung kombiniert, um die Stärken beider Technologien zu nutzen. Diese Ankündigung ist im Wesentlichen eine Fortsetzung der RTX -Ankündigung von NVIDIA von Anfang dieses Jahres. Wenn Sie also der Meinung sind, dass diese Ankündigung ein wenig spärlich ist, dann ist hier der Rest der Geschichte.
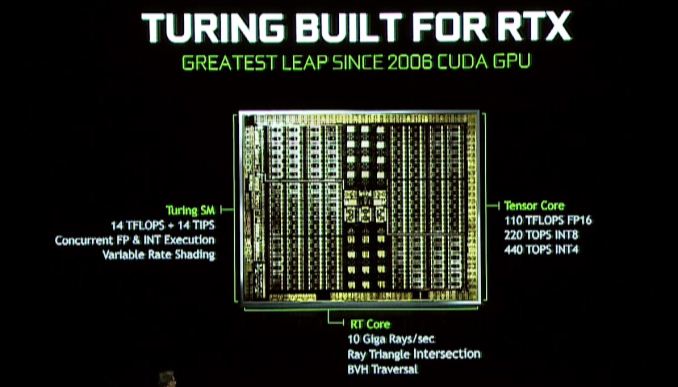
Die große Veränderung hier ist, dass Nvidia noch mehr Ray -Tracing -Hardware mit Turing einbezieht, um eine schnellere und effizientere Beschleunigung der Hardware -Strahlenverfolgung zu bieten. Neu in der Turing -Architektur ist das, was Nvidia als RT -Kern bezeichnet, die Grundlagen, über die wir zu diesem Zeitpunkt nicht vollständig informiert sind, sondern als engagierte Strahlenverfolgungsprozessoren dienen. Diese Prozessorblöcke beschleunigen sowohl die Überprüfungen der Strahl-Dreieck-Kreuzungen als auch die Manipulation des Begrenzungsvolumens (BVH).
Nvidia erklärt, dass das schnellste Geforce -RTX -Teil 10 Milliarden (GIGA) Strahlen pro Sekunde werfen kann, was im Vergleich zum nicht beschleunigten Pascal eine 25 -fache Verbesserung der Strahlenverfolgungsleistung darstellt.
Die Turing -Architektur übertrifft auch die Tensorkerne von Volta, und tatsächlich wurden diese sogar über Volta verstärkt. Die Tensorkerne sind ein wichtiger Aspekt mehrerer Nvidia -Initiativen. Neben der Beschleunigung der Strahlenverfolgung selbst besteht das andere Werkzeug von Nvidia in ihrem Turing -Beutel an Tricks darin, die Menge der in einer Szene erforderlichen Strahlen zu verringern. Natürlich ist das nicht das einzige Feature -Tensor -Kerne, für das Nvidia’s gesamte KI/Neural -Networking -Imperium auf sie basiert. zu einem größeren Bereich von GPUs.
Wenn man sich im Allgemeinen mit dem Hybrid-Rendering befasst, ist es interessant, dass die Gesamtleistung von NVIDIA trotz dieser individuellen Geschwindigkeit nicht ganz so extrem ist. Insgesamt verspricht das Unternehmen einen 6 -fach -Leistungssteiger gegen Pascal, und dies gibt nicht gegen welche Teile festgelegt wird. Die Zeit wird zeigen, ob dies auch bei den RT -Kernen eine realistische Bewertung ist, wie auch bei den RT.
Insbesondere für Gaming -Angelegenheiten sind die Vorteile des hybriden Renderings möglicherweise von Bedeutung, aber es hängt stark davon ab, wie Entwickler es verwenden möchten. Vom Standpunkt der Leistung bin ich nicht sicher, ob es hier viel zu sagen gibt, und das liegt daran. Zugegeben, wenn Sie versuchen, die Ray -Verfolgung auf dem heutigen GPUs zu machen, wäre es extrem langsam – und dadurch eine unglaubliche Beschleunigung -, aber aus diesem Grund verwendet niemand langsame Pfadverfolgungssysteme auf der aktuellen Hardware. Bei Hybrid -Rendering geht es also darum, die Näherungen und Hacks der aktuellen Rasterisierungstechnologie durch genauere Rendering -Methoden zu ersetzen. Mit anderen Worten, weniger „es vorhanden“ und mehr, es zu machen.”

Diese Qualitätsvorteile wiederum sind in der Regel um Beleuchtung, Schatten und Reflexionen zusammengefasst. Alle drei Merkmale basieren von Natur aus auf den Eigenschaften des Lichts, die sich in simplen Hinsicht als Strahl bewegt und die bisher verschiedene Algorithmen die Arbeit oder die „Vorbackszenen“ im Voraus verfälscht haben. Und während die aktuellen Algorithmen ziemlich gut sind, sind sie immer noch nicht nahezu genau. Es gibt also einen klaren Verbesserungsraum.


Nvidia für ihren Teil wirft besonders die globale Beleuchtung um, was eine der schwierigeren Aufgaben ist. Es gibt jedoch auch andere Beleuchtungsmethoden, die ebenfalls davon profitieren, ganz zu schweigen von Reflexionen und Schatten dieser beleuchteten Objekte. Und ehrlich gesagt sind hier Worte ein schlechtes Werkzeug; Es ist schwer zu beschreiben, wie ein Schatten mit Strahlen besser aussieht als ein gefälschter Schatten mit PCSS oder Echtzeitbeleuchtung über vorgebackener Beleuchtung. Aus diesem Grund wird Nvidia, die Grafikkartenfirma, die visuellen Aspekte all dessen schwieriger als je zuvor vorantreiben.
Insgesamt ist das Hybrid -Rendering die Lynchpin -Funktion der Geforce RTX 20 -Serie. Nach ihren Präsentationen von Gamescom und Siggraph ist es klar, dass Nvidia stark in das Feld investiert hat und dass sie den Erfolg der Geforce -Marke in den kommenden Jahren mit dieser Technologie gewettet haben. RT-Kerne und Tensorkerne sind halbfixierte Funktionshardware. Sie können nicht zur Rasterisierung verwendet werden, und die ihnen zugewiesenen Transistoren sind Transistoren, die sonst mehr Rasterisierungshardware gewidmet werden können. Nvidia hat hier in Bezug auf die Opportunitätskosten einen unglaublich bedeutenden Schritt gemacht, indem sie den Hybrid -Rendering -Weg gegangen ist, anstatt einen größeren Pascal zu bauen.
Infolgedessen versucht Nvidia einen Paradigmenwechsel des Verbraucherwechsels, den wir wirklich erst mit der Einführung von Pixel- und Vertex -Shaders (DX8 & DX9 ERA Tech) in den Jahren 2001 und 2002 sehen können. Aus diesem Grund ist die DirectX Raytracing (DXR) -Initiative von Microsoft so wichtig, ebenso wie der andere Entwickler- und Verbraucherinitiativen von NVIDIA. Nvidia muss Verbraucher und Entwickler in dieser Vision des Mischens von Rasterisierung mit Strahlenverfolgung gleich verkaufen, um eine bessere Bildqualität zu bieten. Und mehr als das müssen sie Entwickler in die Idee einlassen, mit spezialisierteren, festen Funktionseinheiten zu arbeiten, da das Gesetz von Moore weiterhin verlangsamt und feste Funktionshardware zu einem Mittel zur größeren Effizienz wird.
Nvidia hat die Farm nicht auf Hybrid -Rendering gewettet, aber sie haben nie versucht, den Markt auf diese Weise zu bewegen. Wenn es also so aussieht, als ob Nvidia auf Hybrid-Rendering und Strahlenverfolgung hyperorientiert ist, liegt das daran, dass sie es sind. Es ist ihre Vision der Zukunft, und jetzt müssen sie alle anderen an Bord bringen.
Turing SM: Dedizierte Int Cores, einheitlicher Cache, variable Ratenschattierung
Neben den dedizierten RT- und Tensor -Kernen lernt die Turing Architecture Streaming Multiprocessor (SM) selbst einige neue Tricks. Insbesondere hier erbt es eine der neueren Änderungen von Volta, bei denen die ganzzahligen Kerne in ihre eigenen Blöcke getrennt waren, anstatt eine Facette des schwimmenden Punktes Cuda -Kerne zu sein. Der Vorteil hier – mindestens so viel wie wir in Volta gesehen haben – ist, dass es die Adresse der Adressgenerierung beschleunigt und die Leistung (Fused Multiply Add (FMA)) erhöht, obwohl es wie bei vielen Aspekten der Turing wahrscheinlich mehr ist (und was es kann, was es kann verwendet werden für) als wir heute sehen.
Der Turing SM enthält auch das, was Nvidia als „einheitliche Cache -Architektur nennt.”Da ich noch auf offizielle SM -Diagramme aus Nvidia warte, ist nicht klar, ob dies die gleiche Art von Vereinigung ist, die wir mit Volta gesehen haben – wo der L1 -Cache mit gemeinsamem Speicher zusammengeführt wurde – oder ob Nvidia einen Schritt weiter gegangen ist. Auf jeden Fall sagt Nvidia, dass es die doppelte Bandbreite der „vorherigen Generation“ anbietet, was unklar ist, ob Nvidia Pascal oder Volta bedeutet (wobei letztere wahrscheinlicher sind).
Schließlich ist auch in der Pressemitteilung von Siggraph Turing versteckt. Dies ist eine relativ junge und bevorstehende Grafik -Rendering -Technik, über die nur begrenzte Informationen vorhanden sind (insbesondere, wie genau Nvidia es implementiert). Aber auf einem sehr hohen Niveau klingt es nach der nächsten Generation der Multi-Res-Schattierungstechnologie von NVIDIA, die es Entwicklern ermöglicht, verschiedene Bereiche eines Bildschirms bei verschiedenen effektiven Auflösungen zu rendern, um die Qualität (und die Zeit) in die Bereiche zu konzentrieren, in denen es sich Es ist das vorteilhafteste.
Füttern des Tieres: GDDR6 -Unterstützung
Da der von GPUs verwendete Speicher von externen Unternehmen entwickelt wird, gibt es hier keine großen Geheimnisse. Die JEDEC und seine großen 3 Mitglieder Samsung, SK Hynix und Micron haben alle GDDR6 -Speicher als Nachfolger für GDDR5 und GDDR5X entwickelt, und Nvidia HA bestätigte, dass Turing es unterstützen wird. Abhängig vom Hersteller wird GDDR6 der ersten Generation im Allgemeinen als bis zu 16 Gbit / s pro Stift der Speicherbandbreite anbietet, was 2x der von GDDR5-Karten der Spät Generation von Nvidia und 40% schneller ist als die letzten GDDR5x-Karten von NVIDIA.
| GPU -Speichermathematik: GDDR6 vs. HBM2 vs. GDDR5X |
Nvidia Geforce RTX 2080 Ti
(GDDR6) | Nvidia Geforce RTX 2080
(GDDR6) | Nvidia Titan v
(HBM2) | Nvidia Titan XP | Nvidia Geforce GTX 1080 Ti | Nvidia Geforce GTX 1080 |
| Gesamtkapazität | 11 GB | 8 GB | 12 GB | 12 GB | 11 GB | 8 GB |
| B/w pro Pin | 14 GB/s | 1.7 GB/s | 11.4 Gbit / s | 11 Gbit / s |
| Chipkapazität | 8 GB (8 GB) | 4 GB (32 GB) | 8 GB (8 GB) |
| NEIN. Chips/kgsds | 11 | 8 | 3 | 12 | 11 | 8 |
| B/w pro Chip/Stack | 56 GB/s | 217.6 GB/s | 45.6 GB/s | 44 GB/s |
| Busbreite | 352-Bit | 256-Bit | 3092-Bit | 384-Bit | 352-Bit | 256-Bit |
| Gesamt b/w | 616 GB/s | 448 GB/s | 652.8 GB/s | 547.7 GB/s | 484 GB/s | 352 GB/s |
| Dramspannung | 1.35 V | 1.2 V (?) | 1.35 V |
In Bezug auf GDDR5X ist GDDR6 nicht ganz so ein Schritt wie einige frühere Speichergenerationen, da viele der Innovationen von GDDR6 bereits in GDDR5x gebacken wurden. Trotzdem wird erwartet, dass neben HBM2 für sehr High -End -Anwendungsfälle der Rückgrat der GPU -Branche wird. Die Hauptänderungen hier umfassen niedrigere Betriebsspannungen (1.35 V), und intern ist der Speicher jetzt in zwei Speicherkanäle pro Chip unterteilt. Für einen Standard-32-Bit-Chip bedeutet dies ein Paar von 16-Bit-Speicherkanälen für insgesamt 16 solcher Kanäle auf einer 256-Bit-Karte. Während dies wiederum bedeutet, dass es eine sehr große Anzahl von Kanälen gibt, ist GPUs auch gut positioniert, um es zu nutzen, da sie zunächst massiv parallele Geräte sind.

NVIDIA für ihren Teil hat bestätigt, dass die ersten Geforce RTX -Karten ihren GDDR6 mit 14 Gbit / s durchführen, was zufällig die schnellste Geschwindigkeitsnote ist, die von allen großen 3 Mitgliedern angeboten wird. Wir wissen, dass Nvidia ausschließlich Samsung GDDR6 für seine Quadro -RTX -Karten verwendet – vermutlich weil sie die Dichte benötigen – für die Geforce RTX -Karten sollte das Feld für alle Speicherhersteller offen sein. Auf lange Sicht lässt dies zwei Wege offen für Karten mit höherer Kapazität: entweder bis zu 16 GB Dichte -Chips oder mit den 8 -GB -Chips, die sie jetzt verwenden, Clamshell gehen.
Chancen & Enden: Nvlink SLI, Virtuallink & 8K HEVC
Dies wurde zwar in der Gamescom-Präsentation von NVIDIA selbst nicht erwähnt, so bestätigt die NVIDIA-Website von GEForce 20 Series, SLI. Insbesondere werden sowohl der RTX 2080 TI als auch das RTX 2080 SLI unterstützen. In der Zwischenzeit wird der RTX 2070 SLI nicht unterstützen; Dies war eine Abreise von der 1070, die es anbot.
Der größere Aspekt dieser Nachricht ist jedoch, dass die proprietäre GPU -Interconnect von NVIDIA, Cache Cohärent, zu Konsumkarten kommen wird. Die GeForce GTX -Karten implementieren SLI über NVLink, wobei 2 NVLink -Kanäle zwischen jeder Karte ausgeführt werden. Bei einer kombinierten 50 GB/Sek. Full-Duplex-Bandbreite-was bedeutet. Dies ist über den anderen NVLINK -Feature -Vorteilen, insbesondere die Cache -Kohärenz. Und all dies kommt zu einem wichtigen Zeitpunkt, da die Bandbreitenanforderungen zwischen-GPU mit jeder Generation weiter steigen.

Nun ist die große Frage, ob dies den anhaltenden Niedergang von SLI umkehren wird, und im Moment verfolge ich einen etwas pessimistischen Ansatz, aber ich bin gespannt darauf, mehr von Nvidia zu hören. 50 GB/s ist eine große Verbesserung gegenüber HB-SLI, aber es ist jedoch nur ein Bruchteil der 448 GB/s (oder mehr) der lokalen Speicherbandbreite, die einer GPU zur Verfügung steht. Daher behebt es also nicht die Probleme, die das Multi-GPU-Rendering verfolgt haben. In dieser Hinsicht ist es wahrscheinlich, dass Nvidia NVLink SLI auf der RTX 2070 nicht unterstützt.
Inzwischen Spieler etwas Neues, auf das man sich für VR freuen kann, mit virtuellem Support Hinzufügen. Der alternative USB-Typ-C-Modus wurde letzten Monat angekündigt und unterstützt 15 W+ Power, 10 Gbit / s USB 3.1 Gen 2 Daten und 4 Fahrspuren von DisplayPort HBR3 -Video über ein einzelnes Kabel. Mit anderen Worten, es ist ein DisplayPort 1.4 Verbindung mit zusätzlichen Daten und Stromversorgung, mit der eine Grafikkarte ein VR -Headset direkt fahren kann. Der Standard wird von Nvidia, AMD, Oculus, Ventil und Microsoft unterstützt. Die Geforce -RTX -Karten werden daher das erste sein, was wir erwarten, letztendlich eine Reihe von Produkten, die den Standard unterstützen.
| Alternative USB-Typ-C-Modi |
| Virtuallink | DisplayPort
(4 Fahrspuren) | DisplayPort
(2 Fahrspuren) | Basis USB-C |
| Videobandbreite (RAW) | 32.4gbit / s | 32.4gbit / s | 16.2Gbit / s | N / A |
| USB 3.x Datenbandbreite | 10gbit / s | N / A | 10gbit / s | 10gbps + 10gbit / s |
| Hochgeschwindigkeitsspurpaare | 6 | 4 |
| Maximale Kraft | Obligatorisch: 15W
Optional: 27W | Optional: bis zu 100 W |
Während Nvidia nur kurz das Thema berührte, wissen wir schließlich, dass ihr Video -Encoder -Block NVENC für Turing aktualisiert wurde. Die neueste Iteration von NVENC fügt speziell Unterstützung für 8K HEVC -Codierung hinzu. In der Zwischenzeit konnte Nvidia auch die Qualität ihres Encoders weiter in Einklang bringen, sodass sie eine ähnliche Qualität wie zuvor mit einem 25% niedrigeren Video -Bitrate erreichen konnten.

Nvidia Geforce RTX 2080 Ti Graphics Card |, offizielle NVIDIA RTX 2080 TI, 2080, & 2070 Spezifikationen, Preis, Erscheinungsdatum | GamersNexus – Gaming -PC -Builds und Hardware -Benchmarks
by • Computerspiele • 0 Comments
2080 Ti Erscheinungsdatum
Nvidia Geforce RTX 2080 Ti Graphics Card
Modded Geforce RTX 2080 TI unterstützt 22 GB GDDR6 -Speicher
Teclab Breaks 3GHz GPU -Uhr Barriere mit GeForce RTX 2080 Ti
Nvidia wurde gemunkelt, Geforce RTX 2080 (TI/Super) und Geforce RTX 2070 (Super) Grafikkarten in den Ruhestand zu nehmen
MSI Outs Geforce RTX 2080 Ti Gaming Z mit 16 Gbit / s GDDR6 -Speicher
Nvidia kündigt Geforce RTX 2080 Ti ‘Cyberpunk 2077 Edition an
Asus zeigt Geforce RTX 2080 Ti ROG Strix White Edition
Gigabyte startet Aorus Gaming Box mit RTX 2080 Ti
Galax Geforce RTX 2080 Ti Hof 10 -jährige Jubiläumsausgabe gepackt
MSI RTX 2080 Ti Lightning 10 -jährige Jubiläumsausgabe Bild
MSI neckt Geforce RTX 2080 Ti Lightning 10 -jährige Jubiläumsausgabe
(PR) MSI kündigt Geforce RTX 2080 Ti Lightning Z an
Evga Geforce RTX 2080 Ti Kingpin Edition ist ein Hybrid
MSI Geforce RTX 2080 Ti Lightning abgebildet
ASUS präsentiert ROG Geforce RTX 2080 Ti Matrix
Buntes Geforce RTX 2080 Ti Igame Kudan lächelt für die Kamera
MSI neckt Kohlenstofffaser Geforce RTX 2080 Ti Lightning Z
Zotac Geforce RTX 2080 Ti Arcticstorm zum Debüt bei CES 2019
MSI Geforce RTX 2080 Ti Lightning Z PCB Abgebildet
Farbenfrohe Starts Geforce RTX 2080 (TI) RNG Edition mit Full Color LCD
(PR) Inno3d kündigt Geforce RTX Ichill Frostbite -Serie an
Evga neckt Geforce RTX 2080 Ti Kingpin
Gigabyte Vorbereitung von Geforce RTX 2080 Ti aorus Turbo
Nvidia bündelt Battlefield V mit Geforce RTX kostenlos
(PR) Manli kündigt Geforce RTX 2080 TI & 2070 mit Blower -Lüfter an
Neuer Kartenbericht Nr. 21: Die RTX RGB Edition
Inno3d verwandelt Geforce RTX -Karte in einen riesigen RGB -Weihnachtsbaum
MSI kündigt Geforce RTX 2080 (TI) Sea Hawk (EK) X -Serie an
Gigabyte neckt Geforce RTX 2080 (TI) AORUS Graphics Card
NVIDIA GEFORCE RTX 2080 TI & RTX 2080 Überprüfungs Roundup
TechPowerup erklärt den Unterschied zwischen Turing A und Nicht-A-GPU-Varianten
Nvidia Geforce RTX 2080 TI und RTX 2080 „Offizielle“ Leistung enthüllt
Die neuen Merkmale der Nvidia Turing Architecture
Nvidia Änderungen Geforce RTX 2080 Bewertungen Datum bis 19. September
Nvidia Geforce RTX 2080 Bewertungen gehen am 17. September live
EVGA enthüllt Hydro -Kupfer- und Hybrid -Geforce -RTX -Modelle
2080 Ti Erscheinungsdatum
Offizielle NVIDIA RTX 2080 TI, 2080 und 2070 Spezifikationen, Preis, Erscheinungsdatum
Von Steve Burke veröffentlicht am 20. August 2018 um 15:00 Uhr
Aktualisieren: Eine Korrektur für SM / CUDA -Kernzahlen hinzugefügt, da die vollständigen Details durchgesickert sind.
NVIDIA kündigte heute seine neuen Turing -Grafikkarten für Gaming an, einschließlich der RTX 2080 TI, RTX 2080 und RTX 2070. Die Karten treten mit einer verbesserten, aber vertrauten Volta-Architektur mit einigen Änderungen an SMS und Speicher voran. Das neue RTX 2080 und 2080 Ti -Schiff zuerst mit Referenzkarten und Partnerkarten weitgehend gleichzeitig (mit einigen fortgeschritteneren Modellen, die 1+ Monat später kommen), Abhängig davon, welcher Partner ist. Die Board -Partner erhielten bis ungefähr zur gleichen Zeit wie die Medien keine Preisgestaltung oder gar Kartennamen. Erwarten Sie daher Verzögerungen in benutzerdefinierten Lösungen. Beachten Sie, dass wir ursprünglich eine 1-3-monatige Latenz auf Partnerkarten gehört haben, aber das scheint nur für fortschrittliche Modelle zu sein, die gerade in die Produktion eintreten. Die meisten Tri-Fan-Modelle sollten am selben Datum verfügbar sein.
Ein weiterer wichtiger Betrachtungsgrund ist die Entscheidung von Nvidia, eine doppeltaxiale Referenzkarte zu verwenden, wodurch ein Großteil des Werts von Partnerkarten am Low-End-. Wenn Sie sich von den Referenzkarten von Gebläber und Dual-Fan-Karten entfernen, werden die Partner des Verwaltungsrats am unmittelbar beeinflusst, was dazu führen könnte. Der RTX 2080 TI kostet 1200 US -Dollar und wird am 20. September mit dem 2080 für 800 US -Dollar (und 20. September) und dem 2070 für 600 US -Dollar (TBD -Veröffentlichungsdatum) gestartet.
Nvidia RTX 2080 TI & 2080 Spezifikationen
Einer der größten Fehler, den die Menschen beim Vergleich neuer GPUs machen, besteht darin, über „Kernzählung zu sprechen.„Dies ist aus wenigen Gründen falsch, von denen eine Kernleistung nicht identisch ist, die die Kreuzarchitektur. Von Kepler bis Pascal gab es für die Effizienz des Gesamtleistung von Per-Watt-Effizienz von über 30%, und nur einen linearen Vergleich zwischen den Kernzählungen enthält dies nicht. Auch Cuda -Kerne sind es nicht Wirklich Wie auch immer Kerne: Sie sind schwimmende Punkteinheiten. Ein SM wäre einem Kern nach Standarddefinitionen ähnlicher, die dazu führen, dass ein Kern in der Lage ist, Anweisungen abzurufen und zu entschlüsseln, diese auszuführen, Daten zu und von Registern und Cache zu lesen und Ergebnisse zu berechnen, und die Ergebnisse der Rechnung zu stellen. Nvidias schwimmende Punkteinheiten können Ergebnisse berechnen, können aber nicht viel von den anderen Zügen tun.
Der Punkt, all dies zu sagen, ist, dass ein strenger Pascal vs. Turing Core -Vergleich muss architektonische Unterschiede berücksichtigen, die sich ändern könnten, wie gut ein „Kern“ funktioniert. Die Leute fielen das letzte Mal in die gleiche Falle.
NVIDIA RTX 2080 TI, 2080 & 2070 Founders Edition Spezifikationen
NVIDIAs neue RTX 2080 TI-Hosts 4352-Gleitkomma-Einheiten, wobei die RTX 2080 Non-TI-Hosting 2944 FPUs veranstaltet. Nvidia hält sich an 64 FPUs pro Streaming -Multiprozessor, die den 2080 Ti mit 68 SMS mit dem 2080 bei 46 SMS belegten. Nvidia hat die SM -Architektur für diese GPU überarbeitet, daher sind wir noch nicht positiv auf alle feineren Details.
Der neue GPUs wechselt auch zu GDDR6, einer erwarteten Verschiebung. Derzeit läuft GDDR6 um ungefähr 20% höhere BOM -Kosten als GDDR5, aber diese Kosten werden im Laufe der Zeit sinken. GDDR6 ermöglicht minimal 14 Gbit / s pro Pin -Durchsatz für die RTX 2080 und 2080 TI, ein bemerkenswerter Schub über die 8 -Gbit / s- und 10 -Gbit / s -Durchsatz bei früheren Generationen. GDDR6 kann auch bis zu 16 Gbit / s pro Pin drücken, aber es gibt kein sofortiges Versprechen für den neuen GPUs. Wir sind uns noch nicht sicher, ob GDDR6 Auswirkungen des Speicherzeitpunkts betrifft. Der 2080 Ti wird 11 GB GDDR6 in einem 352-Bit-Speicherbus mit einer Speicherbandbreite in der Nachbarschaft von 620 GB/s veranstalten. Der RTX 2080 veranstaltet 8 GB GDDR6 an einer 256-Bit-Schnittstelle und ermöglicht daher 448 GB/s Speicherbandbreite.
Fe: 1635 MHz
Fe: 1800 MHz
Fe: 1710MHz
Oder $ 1000*
Oder $ 700*
Oder $ 500*
*Quelle für Preise: NVIDIA -Website. NOTIZ: Wir haben auch gehört, dass die Preise (möglicherweise für Nicht-Fe-Karten? Oder gibt es nur eine Misskommunikation innerhalb von Nvidia?) könnte auch 500 US -Dollar für die 1070, 700 US -Dollar für die 2080 und 1000 US -Dollar für den 2080 Ti betragen. Wir glauben, dass dies Fe vs sein könnte. Referenz, aber es könnte auch von den Nvidia -Teams zu Missverständnissen sein. Im Moment nicht klar.
Nvidia kündigt die Geforce RTX 20 Serie an: RTX 2080 TI & 2080 am September. 20. RTX 2070 im Oktober
Die Keynote Gamescom 2018 von NVIDIA ist gerade abgeschlossen, und wie viele seit seiner Bekanntgabe im letzten Monat erwartet haben, bereitet sich NVIDIA bereit, ihre nächste Generation von Geforce -Hardware zu starten. Angekündigt auf der Veranstaltung und zum Verkauf ab dem 20. September ist die Geforce RTX 20-Serie von NVIDIA, die die derzeitige Pascal-betriebene Geforce GTX 10-Serie auftritt. Basierend auf der neuen Turing -GPU -Architektur von NVIDIA und basiert auf dem 12nm -FFN -Prozess von TSMC. Nvidia hat hohe Ziele. Sie möchten eine gesamte Paradigmenverschiebung bei der Rendite von Spielen und der Bewertung von PC. CEO Jensen Huang hat die wichtigste GPU -Architektur von Turing Nvidia seit 2006 Tesla GPU Architecture (G80 GPU) bezeichnet. Aus Merkmal.
Wie traditionell sind die ersten Karten aus dem Nvidia-Stall die High-End-Karten. In einer ziemlich beträchtlichen Pause aus der Tradition werden wir nicht nur die X80- und X70 -Karten zum Start erhalten, sondern auch die X80 Ti -Karte. Dies bedeutet. Der Produktstack von NVIDIA bleibt hier unverändert, daher bleibt RTX 2080 Ti ihre Flaggschiff-Karte, während RTX 2080 ihre High-End-Karte ist, und dann RTX 2070 die etwas billigere Karte, um Enthusiasten zu verleihen, ohne die Bank zu brechen.
Alle drei Karten werden in den nächsten zwei Monaten gestartet. Zunächst wird der RTX 2080 TI und RTX 2080 sein, der am 20. September starten wird . Der RTX 2080 TI startet bei 999 US -Dollar für Partnerkarten, während der RTX 2080 bei 699 US -Dollar beginnt. In der Zwischenzeit wird der RTX 2070 irgendwann im Oktober mit Partnerkarten ab 499 US -Dollar gestartet. Auf historischer Basis sind alle diese Preise höher als die letzte Generation zwischen 120 und 300 US -Dollar. In der Zwischenzeit sind Nvidia’s eigene Referenzqualitäts-Gründer-Edition-Karten wieder zurück, und diese werden eine Prämie von 100 bis 200 US-Dollar gegenüber den Basispreisen tragen.
Leider nimmt Nvidia hier bereits Vorbestellungen an, sodass die Verbraucher im Wesentlichen einen „Blind Buy“ machen müssen. Nvidia hat überraschend wenig Informationen über die Leistung angeboten, und wir empfehlen, auf vertrauenswürdige Bewertungen von Drittanbietern zu warten (i.e. US), aber ich muss zugeben, dass ich mir nicht vorstellen kann, dass es viel Aktien gibt, die die Bewertungen auf die Straße machen werden.
(Int4)
Gründer $ 1199
Gründer $ 799
Gründer $ 599
Gründer $ 699
Turing Architecture von Nvidia: RT & Tensor Cores
Was bringt Turing also auf den Tisch?? Das Festzelt -Feature auf ganzer Linie ist das Hybrid -Rendering, das die Strahlenverfolgung mit der traditionellen Rasterisierung kombiniert, um die Stärken beider Technologien zu nutzen. Diese Ankündigung ist im Wesentlichen eine Fortsetzung der RTX -Ankündigung von NVIDIA von Anfang dieses Jahres. Wenn Sie also der Meinung sind, dass diese Ankündigung ein wenig spärlich ist, dann ist hier der Rest der Geschichte.
Die große Veränderung hier ist, dass Nvidia noch mehr Ray -Tracing -Hardware mit Turing einbezieht, um eine schnellere und effizientere Beschleunigung der Hardware -Strahlenverfolgung zu bieten. Neu in der Turing -Architektur ist das, was Nvidia als RT -Kern bezeichnet, die Grundlagen, über die wir zu diesem Zeitpunkt nicht vollständig informiert sind, sondern als engagierte Strahlenverfolgungsprozessoren dienen. Diese Prozessorblöcke beschleunigen sowohl die Überprüfungen der Strahl-Dreieck-Kreuzungen als auch die Manipulation des Begrenzungsvolumens (BVH).
Nvidia erklärt, dass das schnellste Geforce -RTX -Teil 10 Milliarden (GIGA) Strahlen pro Sekunde werfen kann, was im Vergleich zum nicht beschleunigten Pascal eine 25 -fache Verbesserung der Strahlenverfolgungsleistung darstellt.
Die Turing -Architektur übertrifft auch die Tensorkerne von Volta, und tatsächlich wurden diese sogar über Volta verstärkt. Die Tensorkerne sind ein wichtiger Aspekt mehrerer Nvidia -Initiativen. Neben der Beschleunigung der Strahlenverfolgung selbst besteht das andere Werkzeug von Nvidia in ihrem Turing -Beutel an Tricks darin, die Menge der in einer Szene erforderlichen Strahlen zu verringern. Natürlich ist das nicht das einzige Feature -Tensor -Kerne, für das Nvidia’s gesamte KI/Neural -Networking -Imperium auf sie basiert. zu einem größeren Bereich von GPUs.
Wenn man sich im Allgemeinen mit dem Hybrid-Rendering befasst, ist es interessant, dass die Gesamtleistung von NVIDIA trotz dieser individuellen Geschwindigkeit nicht ganz so extrem ist. Insgesamt verspricht das Unternehmen einen 6 -fach -Leistungssteiger gegen Pascal, und dies gibt nicht gegen welche Teile festgelegt wird. Die Zeit wird zeigen, ob dies auch bei den RT -Kernen eine realistische Bewertung ist, wie auch bei den RT.
Insbesondere für Gaming -Angelegenheiten sind die Vorteile des hybriden Renderings möglicherweise von Bedeutung, aber es hängt stark davon ab, wie Entwickler es verwenden möchten. Vom Standpunkt der Leistung bin ich nicht sicher, ob es hier viel zu sagen gibt, und das liegt daran. Zugegeben, wenn Sie versuchen, die Ray -Verfolgung auf dem heutigen GPUs zu machen, wäre es extrem langsam – und dadurch eine unglaubliche Beschleunigung -, aber aus diesem Grund verwendet niemand langsame Pfadverfolgungssysteme auf der aktuellen Hardware. Bei Hybrid -Rendering geht es also darum, die Näherungen und Hacks der aktuellen Rasterisierungstechnologie durch genauere Rendering -Methoden zu ersetzen. Mit anderen Worten, weniger „es vorhanden“ und mehr, es zu machen.”
Diese Qualitätsvorteile wiederum sind in der Regel um Beleuchtung, Schatten und Reflexionen zusammengefasst. Alle drei Merkmale basieren von Natur aus auf den Eigenschaften des Lichts, die sich in simplen Hinsicht als Strahl bewegt und die bisher verschiedene Algorithmen die Arbeit oder die „Vorbackszenen“ im Voraus verfälscht haben. Und während die aktuellen Algorithmen ziemlich gut sind, sind sie immer noch nicht nahezu genau. Es gibt also einen klaren Verbesserungsraum.
Nvidia für ihren Teil wirft besonders die globale Beleuchtung um, was eine der schwierigeren Aufgaben ist. Es gibt jedoch auch andere Beleuchtungsmethoden, die ebenfalls davon profitieren, ganz zu schweigen von Reflexionen und Schatten dieser beleuchteten Objekte. Und ehrlich gesagt sind hier Worte ein schlechtes Werkzeug; Es ist schwer zu beschreiben, wie ein Schatten mit Strahlen besser aussieht als ein gefälschter Schatten mit PCSS oder Echtzeitbeleuchtung über vorgebackener Beleuchtung. Aus diesem Grund wird Nvidia, die Grafikkartenfirma, die visuellen Aspekte all dessen schwieriger als je zuvor vorantreiben.
Insgesamt ist das Hybrid -Rendering die Lynchpin -Funktion der Geforce RTX 20 -Serie. Nach ihren Präsentationen von Gamescom und Siggraph ist es klar, dass Nvidia stark in das Feld investiert hat und dass sie den Erfolg der Geforce -Marke in den kommenden Jahren mit dieser Technologie gewettet haben. RT-Kerne und Tensorkerne sind halbfixierte Funktionshardware. Sie können nicht zur Rasterisierung verwendet werden, und die ihnen zugewiesenen Transistoren sind Transistoren, die sonst mehr Rasterisierungshardware gewidmet werden können. Nvidia hat hier in Bezug auf die Opportunitätskosten einen unglaublich bedeutenden Schritt gemacht, indem sie den Hybrid -Rendering -Weg gegangen ist, anstatt einen größeren Pascal zu bauen.
Infolgedessen versucht Nvidia einen Paradigmenwechsel des Verbraucherwechsels, den wir wirklich erst mit der Einführung von Pixel- und Vertex -Shaders (DX8 & DX9 ERA Tech) in den Jahren 2001 und 2002 sehen können. Aus diesem Grund ist die DirectX Raytracing (DXR) -Initiative von Microsoft so wichtig, ebenso wie der andere Entwickler- und Verbraucherinitiativen von NVIDIA. Nvidia muss Verbraucher und Entwickler in dieser Vision des Mischens von Rasterisierung mit Strahlenverfolgung gleich verkaufen, um eine bessere Bildqualität zu bieten. Und mehr als das müssen sie Entwickler in die Idee einlassen, mit spezialisierteren, festen Funktionseinheiten zu arbeiten, da das Gesetz von Moore weiterhin verlangsamt und feste Funktionshardware zu einem Mittel zur größeren Effizienz wird.
Nvidia hat die Farm nicht auf Hybrid -Rendering gewettet, aber sie haben nie versucht, den Markt auf diese Weise zu bewegen. Wenn es also so aussieht, als ob Nvidia auf Hybrid-Rendering und Strahlenverfolgung hyperorientiert ist, liegt das daran, dass sie es sind. Es ist ihre Vision der Zukunft, und jetzt müssen sie alle anderen an Bord bringen.
Turing SM: Dedizierte Int Cores, einheitlicher Cache, variable Ratenschattierung
Neben den dedizierten RT- und Tensor -Kernen lernt die Turing Architecture Streaming Multiprocessor (SM) selbst einige neue Tricks. Insbesondere hier erbt es eine der neueren Änderungen von Volta, bei denen die ganzzahligen Kerne in ihre eigenen Blöcke getrennt waren, anstatt eine Facette des schwimmenden Punktes Cuda -Kerne zu sein. Der Vorteil hier – mindestens so viel wie wir in Volta gesehen haben – ist, dass es die Adresse der Adressgenerierung beschleunigt und die Leistung (Fused Multiply Add (FMA)) erhöht, obwohl es wie bei vielen Aspekten der Turing wahrscheinlich mehr ist (und was es kann, was es kann verwendet werden für) als wir heute sehen.
Der Turing SM enthält auch das, was Nvidia als „einheitliche Cache -Architektur nennt.”Da ich noch auf offizielle SM -Diagramme aus Nvidia warte, ist nicht klar, ob dies die gleiche Art von Vereinigung ist, die wir mit Volta gesehen haben – wo der L1 -Cache mit gemeinsamem Speicher zusammengeführt wurde – oder ob Nvidia einen Schritt weiter gegangen ist. Auf jeden Fall sagt Nvidia, dass es die doppelte Bandbreite der „vorherigen Generation“ anbietet, was unklar ist, ob Nvidia Pascal oder Volta bedeutet (wobei letztere wahrscheinlicher sind).
Schließlich ist auch in der Pressemitteilung von Siggraph Turing versteckt. Dies ist eine relativ junge und bevorstehende Grafik -Rendering -Technik, über die nur begrenzte Informationen vorhanden sind (insbesondere, wie genau Nvidia es implementiert). Aber auf einem sehr hohen Niveau klingt es nach der nächsten Generation der Multi-Res-Schattierungstechnologie von NVIDIA, die es Entwicklern ermöglicht, verschiedene Bereiche eines Bildschirms bei verschiedenen effektiven Auflösungen zu rendern, um die Qualität (und die Zeit) in die Bereiche zu konzentrieren, in denen es sich Es ist das vorteilhafteste.
Füttern des Tieres: GDDR6 -Unterstützung
Da der von GPUs verwendete Speicher von externen Unternehmen entwickelt wird, gibt es hier keine großen Geheimnisse. Die JEDEC und seine großen 3 Mitglieder Samsung, SK Hynix und Micron haben alle GDDR6 -Speicher als Nachfolger für GDDR5 und GDDR5X entwickelt, und Nvidia HA bestätigte, dass Turing es unterstützen wird. Abhängig vom Hersteller wird GDDR6 der ersten Generation im Allgemeinen als bis zu 16 Gbit / s pro Stift der Speicherbandbreite anbietet, was 2x der von GDDR5-Karten der Spät Generation von Nvidia und 40% schneller ist als die letzten GDDR5x-Karten von NVIDIA.
(GDDR6)
(GDDR6)
(HBM2)
In Bezug auf GDDR5X ist GDDR6 nicht ganz so ein Schritt wie einige frühere Speichergenerationen, da viele der Innovationen von GDDR6 bereits in GDDR5x gebacken wurden. Trotzdem wird erwartet, dass neben HBM2 für sehr High -End -Anwendungsfälle der Rückgrat der GPU -Branche wird. Die Hauptänderungen hier umfassen niedrigere Betriebsspannungen (1.35 V), und intern ist der Speicher jetzt in zwei Speicherkanäle pro Chip unterteilt. Für einen Standard-32-Bit-Chip bedeutet dies ein Paar von 16-Bit-Speicherkanälen für insgesamt 16 solcher Kanäle auf einer 256-Bit-Karte. Während dies wiederum bedeutet, dass es eine sehr große Anzahl von Kanälen gibt, ist GPUs auch gut positioniert, um es zu nutzen, da sie zunächst massiv parallele Geräte sind.
NVIDIA für ihren Teil hat bestätigt, dass die ersten Geforce RTX -Karten ihren GDDR6 mit 14 Gbit / s durchführen, was zufällig die schnellste Geschwindigkeitsnote ist, die von allen großen 3 Mitgliedern angeboten wird. Wir wissen, dass Nvidia ausschließlich Samsung GDDR6 für seine Quadro -RTX -Karten verwendet – vermutlich weil sie die Dichte benötigen – für die Geforce RTX -Karten sollte das Feld für alle Speicherhersteller offen sein. Auf lange Sicht lässt dies zwei Wege offen für Karten mit höherer Kapazität: entweder bis zu 16 GB Dichte -Chips oder mit den 8 -GB -Chips, die sie jetzt verwenden, Clamshell gehen.
Chancen & Enden: Nvlink SLI, Virtuallink & 8K HEVC
Dies wurde zwar in der Gamescom-Präsentation von NVIDIA selbst nicht erwähnt, so bestätigt die NVIDIA-Website von GEForce 20 Series, SLI. Insbesondere werden sowohl der RTX 2080 TI als auch das RTX 2080 SLI unterstützen. In der Zwischenzeit wird der RTX 2070 SLI nicht unterstützen; Dies war eine Abreise von der 1070, die es anbot.
Der größere Aspekt dieser Nachricht ist jedoch, dass die proprietäre GPU -Interconnect von NVIDIA, Cache Cohärent, zu Konsumkarten kommen wird. Die GeForce GTX -Karten implementieren SLI über NVLink, wobei 2 NVLink -Kanäle zwischen jeder Karte ausgeführt werden. Bei einer kombinierten 50 GB/Sek. Full-Duplex-Bandbreite-was bedeutet. Dies ist über den anderen NVLINK -Feature -Vorteilen, insbesondere die Cache -Kohärenz. Und all dies kommt zu einem wichtigen Zeitpunkt, da die Bandbreitenanforderungen zwischen-GPU mit jeder Generation weiter steigen.
Nun ist die große Frage, ob dies den anhaltenden Niedergang von SLI umkehren wird, und im Moment verfolge ich einen etwas pessimistischen Ansatz, aber ich bin gespannt darauf, mehr von Nvidia zu hören. 50 GB/s ist eine große Verbesserung gegenüber HB-SLI, aber es ist jedoch nur ein Bruchteil der 448 GB/s (oder mehr) der lokalen Speicherbandbreite, die einer GPU zur Verfügung steht. Daher behebt es also nicht die Probleme, die das Multi-GPU-Rendering verfolgt haben. In dieser Hinsicht ist es wahrscheinlich, dass Nvidia NVLink SLI auf der RTX 2070 nicht unterstützt.
Inzwischen Spieler etwas Neues, auf das man sich für VR freuen kann, mit virtuellem Support Hinzufügen. Der alternative USB-Typ-C-Modus wurde letzten Monat angekündigt und unterstützt 15 W+ Power, 10 Gbit / s USB 3.1 Gen 2 Daten und 4 Fahrspuren von DisplayPort HBR3 -Video über ein einzelnes Kabel. Mit anderen Worten, es ist ein DisplayPort 1.4 Verbindung mit zusätzlichen Daten und Stromversorgung, mit der eine Grafikkarte ein VR -Headset direkt fahren kann. Der Standard wird von Nvidia, AMD, Oculus, Ventil und Microsoft unterstützt. Die Geforce -RTX -Karten werden daher das erste sein, was wir erwarten, letztendlich eine Reihe von Produkten, die den Standard unterstützen.
(4 Fahrspuren)
(2 Fahrspuren)
Optional: 27W
Während Nvidia nur kurz das Thema berührte, wissen wir schließlich, dass ihr Video -Encoder -Block NVENC für Turing aktualisiert wurde. Die neueste Iteration von NVENC fügt speziell Unterstützung für 8K HEVC -Codierung hinzu. In der Zwischenzeit konnte Nvidia auch die Qualität ihres Encoders weiter in Einklang bringen, sodass sie eine ähnliche Qualität wie zuvor mit einem 25% niedrigeren Video -Bitrate erreichen konnten.